 Твитнуть
Твитнуть
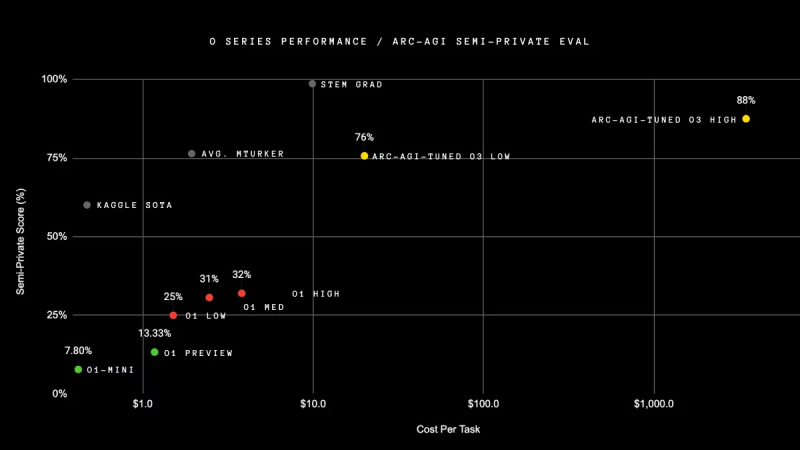
Как утверждает OpenAI, ее новая модель o3 превосходит предыдущие рекорды производительности по всем направлениям. В рамках теста ARC-AGI, который был специально создан для сравнения возможностей искусственного интеллекта с интеллектом человека, модель o3 более чем в три раза превзошла возможности o1, продемонстрировав результат в 88%.
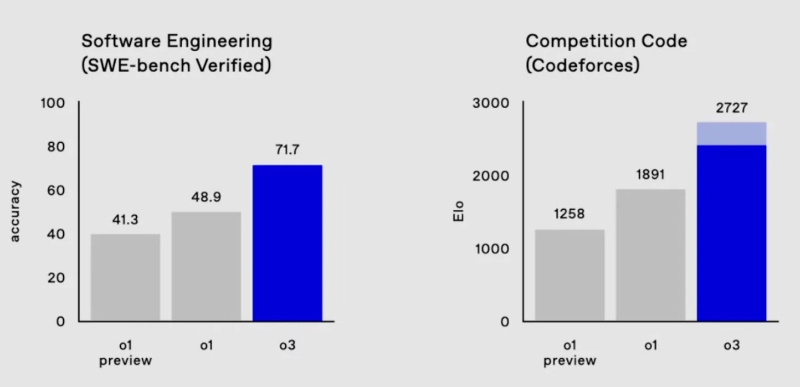
Новая модель также быстрее предшественника в написании кода (тест SWE-Bench Verified) на 22,8% и даже превзошла ведущего ученого OpenAI в спортивном программировании.
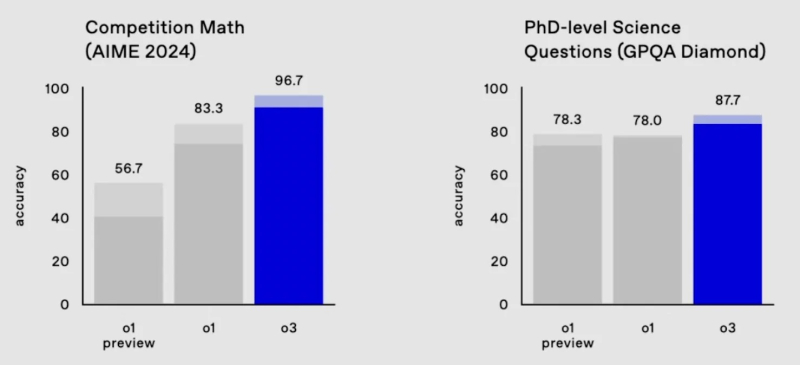
Модель o3 почти справилась с одним из самых сложных математических тестов, AIME 2024, пропустив в нем лишь один вопрос, а также набрала в бенчмарке GPQA Diamond 87,7% значительно больше, чем любой результат человека-эксперта.
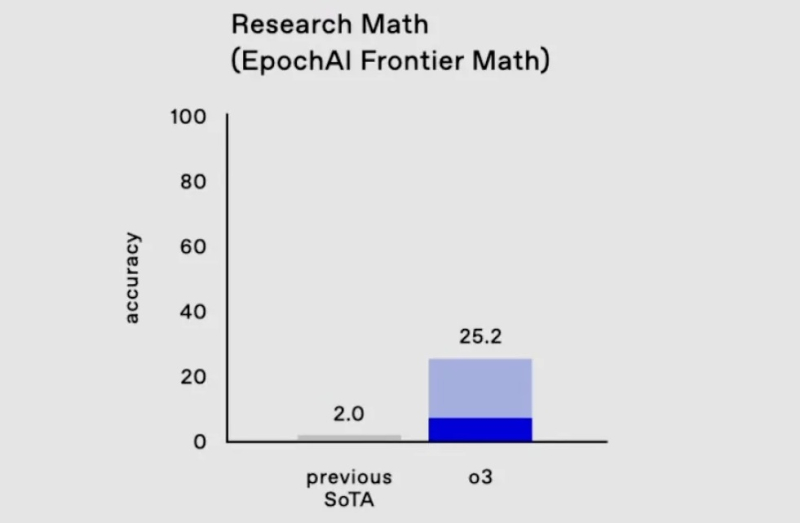
В самых сложных математических и логических тестах, которые обычно ставят в тупик любые другие ИИ, o3 решила 25,2% задач результаты других моделей не превышают и 2%.
Весомым преимуществом o3, как и o1, является возможность моделей "рассуждать" и эффективно проверять свои же факты, чтобы избегать различного рода ошибок и галлюцинаций. Правда, разработчики из OpenAI заявили, что процесс проверки фактов перед выдачей ответа приводит к небольшой задержке от нескольких секунд до нескольких минут (зависит от сложности вопроса). Кроме того, задержка связана с тем, что модель определяет, соответствует ли запрос пользователя политике безопасности OpenAI. Компания утверждает, что при тестировании нового алгоритма защиты на o1 она намного лучше следовала правилам безопасности, чем предыдущие модели, включая GPT-4.
Новая модель также быстрее предшественника в написании кода (тест SWE-Bench Verified) на 22,8% и даже превзошла ведущего ученого OpenAI в спортивном программировании.
Модель o3 почти справилась с одним из самых сложных математических тестов, AIME 2024, пропустив в нем лишь один вопрос, а также набрала в бенчмарке GPQA Diamond 87,7% значительно больше, чем любой результат человека-эксперта.
В самых сложных математических и логических тестах, которые обычно ставят в тупик любые другие ИИ, o3 решила 25,2% задач результаты других моделей не превышают и 2%.
Весомым преимуществом o3, как и o1, является возможность моделей "рассуждать" и эффективно проверять свои же факты, чтобы избегать различного рода ошибок и галлюцинаций. Правда, разработчики из OpenAI заявили, что процесс проверки фактов перед выдачей ответа приводит к небольшой задержке от нескольких секунд до нескольких минут (зависит от сложности вопроса). Кроме того, задержка связана с тем, что модель определяет, соответствует ли запрос пользователя политике безопасности OpenAI. Компания утверждает, что при тестировании нового алгоритма защиты на o1 она намного лучше следовала правилам безопасности, чем предыдущие модели, включая GPT-4.



Комментарий