 Твитнуть
Твитнуть
OpenAI представляет новую большую языковую модель o1, обученную с помощью обучения с подкреплением для выполнения сложных рассуждений. o1 думает, прежде чем ответить она может создать длинную внутреннюю цепочку рассуждений, прежде чем ответить пользователю.

OpenAI o1 занимает 89-й процентиль по вопросам соревновательного программирования (Codeforces), входит в число 500 лучших студентов США в квалификационном раунде для участия в Олимпиаде по математике (AIME) и превосходит точность людей с докторской степенью (PhD - доктор философии) на эталонном тесте по физике, биологии и химии (GPQA). Хотя работа, необходимая для того, чтобы сделать эту новую модель такой же удобной в использовании, как и текущие модели, все еще продолжается, OpenAI выпускает раннюю версию этой модели, o1-preview, для немедленного использования в ChatGPT и для доверенных пользователей API.
Алгоритм обучения с подкреплением в больших масштабах учит модель продуктивно мыслить, используя свою цепочку рассуждений в высокоэффективном, с точки зрения данных, процессе обучения. В OpenAI обнаружили, что производительность o1 последовательно улучшается с увеличением объема обучения с подкреплением (вычислительных ресурсов во время обучения) и с увеличением времени, затрачиваемого на размышления (вычислительных ресурсов во время тестирования). Ограничения на масштабирование этого подхода существенно отличаются от ограничений предварительного обучения больших языковых моделей, и разработчики продолжают их исследовать.

Производительность o1 плавно улучшается как с увеличением вычислительных ресурсов во время обучения, так и с увеличением вычислительных ресурсов во время тестирования.
Оценка
Чтобы подчеркнуть улучшение рассуждений по сравнению с GPT-4o, в OpenAI протестировали модели на разнообразном наборе экзаменов для людей и бенчмарков машинного обучения. Разработчики показывают, что o1 значительно превосходит GPT-4o в подавляющем большинстве этих задач, требующих интенсивного использования логического мышления. Если не указано иное, они оценивали o1 в режиме максимального использования вычислительных ресурсов во время тестирования.

o1 значительно превосходит GPT-4o на сложных бенчмарках, оценивающих способность к рассуждению. Сплошные столбцы показывают точность pass@1, а затененная область показывает производительность голосования большинством (консенсуса) с 64 выборками.
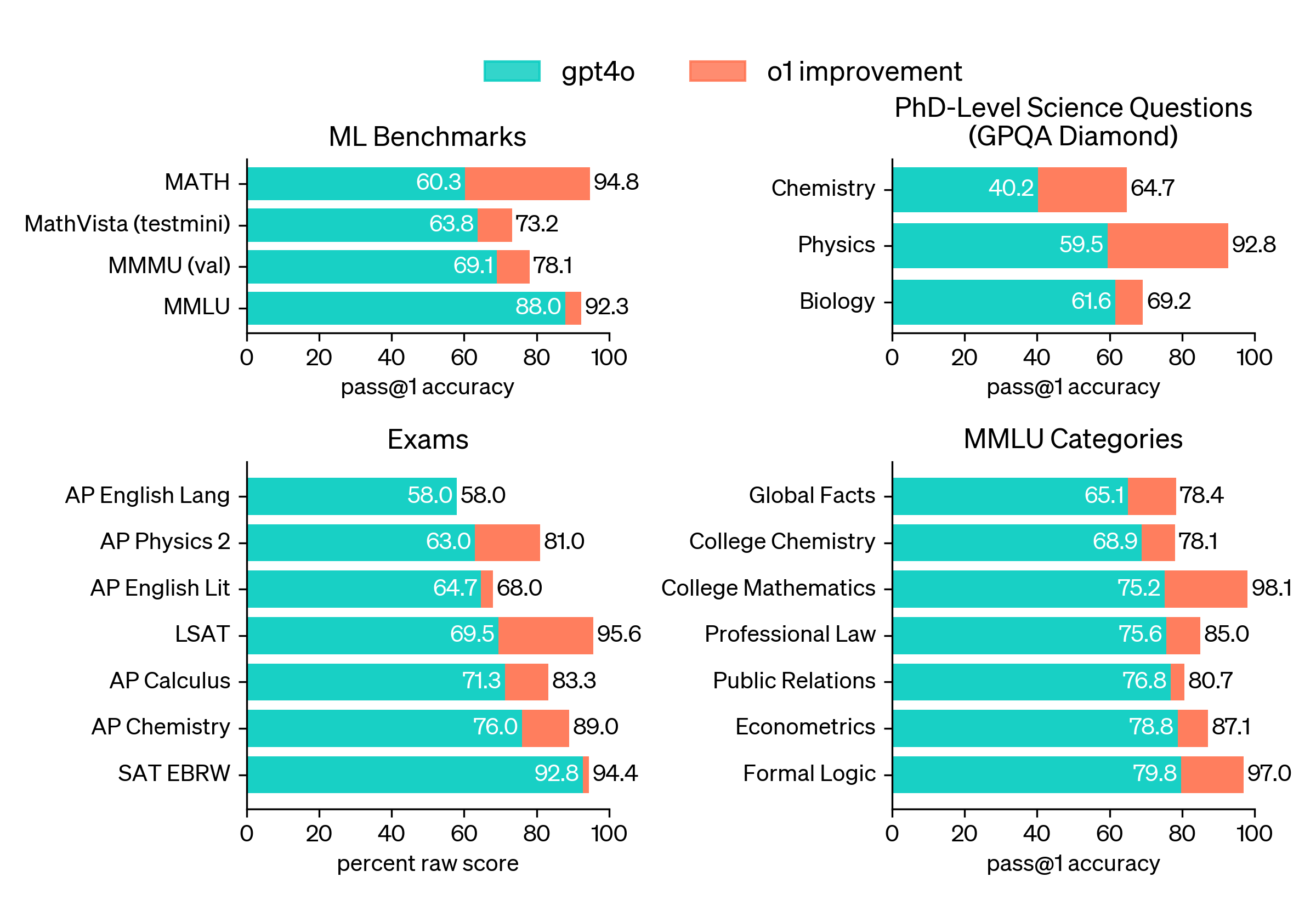
o1 превосходит GPT-4o на широком спектре бенчмарков, включая 54 из 57 подкатегорий MMLU. Для иллюстрации показаны семь из них.
Во многих бенчмарках, требующих интенсивного использования логического мышления, o1 соперничает по производительности с экспертами-людьми. Новейшие передовые модели настолько хорошо справляются с MATH и GSM8K, что эти бенчмарки больше не эффективны для дифференциации моделей. В OpenAI оценили математическую производительность на AIME, экзамене, предназначенном для проверки самых ярких старшеклассников-математиков в Америке. На экзаменах AIME 2024 года GPT-4o решал в среднем только 12% (1,8/15) задач. o1 в среднем решал 74% (11,1/15) с одной выборкой на задачу, 83% (12,5/15) с консенсусом среди 64 выборок и 93% (13,9/15) при повторном ранжировании 1000 выборок с помощью обученной функции оценки. Счет 13,9 помещает его в число 500 лучших студентов страны и выше порога для участия в математической олимпиаде США.
В OpenAI также оценили o1 на GPQA Diamond, сложном бенчмарке интеллекта, который проверяет знания в области химии, физики и биологии. Чтобы сравнить модели с людьми, разработчики наняли экспертов с докторскими степенями для ответа на вопросы GPQA Diamond. Они обнаружили, что o1 превзошел производительность этих экспертов-людей, став первой моделью, сделавшей это на этом бенчмарке. Эти результаты не означают, что o1 во всех отношениях способнее, чем человек с докторской степенью, только то, что модель более искусна в решении некоторых задач, которые, как ожидается, должен решать человек с докторской степенью. На нескольких других бенчмарках машинного обучения o1 улучшил показатели по сравнению с самыми современными моделями. С включенными возможностями визуального восприятия o1 набрал 78,2% на MMMU, став первой моделью, способной конкурировать с экспертами-людьми. Он также превзошел GPT-4o в 54 из 57 подкатегорий MMLU.
Цепочка рассуждений
Подобно тому, как человек может долго думать, прежде чем ответить на сложный вопрос, o1 использует цепочку рассуждений при попытке решить задачу. Благодаря обучению с подкреплением o1 учится оттачивать свою цепочку рассуждений и совершенствовать используемые стратегии. Он учится распознавать и исправлять свои ошибки. Он учится разбивать сложные шаги на более простые. Он учится пробовать другой подход, когда текущий не работает. Этот процесс значительно улучшает способность модели к рассуждению.
Программирование
В OpenAI обучили модель, которая набрала 213 баллов и заняла 49-й процентиль на Международной олимпиаде по информатике (IOI) 2024 года, инициализировав ее из o1 и обучив дальнейшему совершенствованию навыков программирования. Эта модель участвовала в IOI 2024 года на тех же условиях, что и участники-люди. У нее было десять часов, чтобы решить шесть сложных алгоритмических задач, и ей разрешалось 50 попыток на задачу.
Для каждой задачи система генерировала множество вариантов решений и отправляла 50 из них на основе стратегии выбора во время тестирования. Решения выбирались на основе производительности на общедоступных тестовых случаях IOI, тестовых случаях, сгенерированных моделью, и обученной функции оценки. Если бы разработчики вместо этого отправляли решения случайным образом, они бы набрали в среднем всего 156 баллов, что говорит о том, что эта стратегия стоила почти 60 баллов в условиях соревнований.
При ослабленном ограничении на количество попыток разработчики обнаружили, что производительность модели значительно улучшилась. При разрешении 10 000 попыток на задачу модель достигла результата 362,14 балла выше порога золотой медали даже без какой-либо стратегии выбора во время тестирования.
Наконец, в OpenAI смоделировали соревнования по программированию, проводимые Codeforces, чтобы продемонстрировать навыки программирования этой модели. Их оценки точно соответствовали правилам соревнований и допускали 10 попыток. GPT-4o достиг рейтинга Эло 808, что соответствует 11-му процентилю среди участников-людей. Эта модель значительно превзошла как GPT-4o, так и o1 она достигла рейтинга Эло 1807, превзойдя 93% участников.

Дальнейшая тонкая настройка на соревнованиях по программированию улучшает o1. Улучшенная модель заняла 49-й процентиль на Международной олимпиаде по информатике 2024 года в соответствии с правилами соревнований.
Оценка человеческих предпочтений
В дополнение к экзаменам и академическим бенчмаркам в OpenAI также оценили предпочтения людей в отношении o1-preview по сравнению с GPT-4o на сложных, открытых запросах в широком спектре областей. В этой оценке людям-оценщикам были показаны анонимные ответы на запрос от o1-preview и GPT-4o, и они проголосовали за то, какой ответ им больше понравился. o1-preview значительно предпочтительнее GPT-4o в категориях, требующих интенсивного использования логического мышления, таких как анализ данных, программирование и математика. Однако o1-preview не является предпочтительным в некоторых задачах обработки естественного языка, что говорит о том, что он не подходит для всех случаев использования.

Люди предпочитают o1-preview в областях, где полезны мощные рассуждения.
Безопасность
Цепочка рассуждений предоставляет новые возможности для согласования и безопасности. В OpenAI обнаружили, что интеграция их политик поведения модели в цепочку рассуждений модели является эффективным способом надежного обучения человеческим ценностям и принципам. Обучая модель правилам безопасности и тому, как рассуждать о них в контексте, разработчики обнаружили доказательства того, что способность к рассуждению напрямую влияет на надежность модели: o1-preview добился существенного улучшения производительности в ключевых оценках взлома и самых сложных внутренних бенчмарках компании для оценки границ отказа модели в отношении безопасности. Разработчики считают, что использование цепочки рассуждений предлагает значительные преимущества для безопасности и согласования, потому что оно позволяет им наблюдать за мышлением модели понятным образом, и рассуждения модели о правилах безопасности более устойчивы к сценариям, выходящим за рамки распределения.
Чтобы подвергнуть улучшения стресс-тестированию, в OpenAI провели набор тестов безопасности и red-teaming перед развертыванием в соответствии с системой готовности. Разработчики обнаружили, что цепочка рассуждений способствовала улучшению возможностей во всех их оценках. Особо следует отметить, что они наблюдали интересные случаи взлома вознаграждения. Подробные результаты этих оценок можно найти в прилагаемой системной карте o1 на сайте OpenAI.
Заключение
o1 значительно продвигает современные технологии в области рассуждений ИИ. В OpenAI планируют выпускать улучшенные версии этой модели по мере продолжения итераций. Они ожидают, что эти новые возможности рассуждения улучшат их способность согласовывать модели с человеческими ценностями и принципами. Они считают, что o1 и его преемники откроют множество новых вариантов использования ИИ в науке, программировании, математике и смежных областях.
OpenAI o1 занимает 89-й процентиль по вопросам соревновательного программирования (Codeforces), входит в число 500 лучших студентов США в квалификационном раунде для участия в Олимпиаде по математике (AIME) и превосходит точность людей с докторской степенью (PhD - доктор философии) на эталонном тесте по физике, биологии и химии (GPQA). Хотя работа, необходимая для того, чтобы сделать эту новую модель такой же удобной в использовании, как и текущие модели, все еще продолжается, OpenAI выпускает раннюю версию этой модели, o1-preview, для немедленного использования в ChatGPT и для доверенных пользователей API.
Алгоритм обучения с подкреплением в больших масштабах учит модель продуктивно мыслить, используя свою цепочку рассуждений в высокоэффективном, с точки зрения данных, процессе обучения. В OpenAI обнаружили, что производительность o1 последовательно улучшается с увеличением объема обучения с подкреплением (вычислительных ресурсов во время обучения) и с увеличением времени, затрачиваемого на размышления (вычислительных ресурсов во время тестирования). Ограничения на масштабирование этого подхода существенно отличаются от ограничений предварительного обучения больших языковых моделей, и разработчики продолжают их исследовать.
Производительность o1 плавно улучшается как с увеличением вычислительных ресурсов во время обучения, так и с увеличением вычислительных ресурсов во время тестирования.
Оценка
Чтобы подчеркнуть улучшение рассуждений по сравнению с GPT-4o, в OpenAI протестировали модели на разнообразном наборе экзаменов для людей и бенчмарков машинного обучения. Разработчики показывают, что o1 значительно превосходит GPT-4o в подавляющем большинстве этих задач, требующих интенсивного использования логического мышления. Если не указано иное, они оценивали o1 в режиме максимального использования вычислительных ресурсов во время тестирования.
o1 значительно превосходит GPT-4o на сложных бенчмарках, оценивающих способность к рассуждению. Сплошные столбцы показывают точность pass@1, а затененная область показывает производительность голосования большинством (консенсуса) с 64 выборками.
o1 превосходит GPT-4o на широком спектре бенчмарков, включая 54 из 57 подкатегорий MMLU. Для иллюстрации показаны семь из них.
Во многих бенчмарках, требующих интенсивного использования логического мышления, o1 соперничает по производительности с экспертами-людьми. Новейшие передовые модели настолько хорошо справляются с MATH и GSM8K, что эти бенчмарки больше не эффективны для дифференциации моделей. В OpenAI оценили математическую производительность на AIME, экзамене, предназначенном для проверки самых ярких старшеклассников-математиков в Америке. На экзаменах AIME 2024 года GPT-4o решал в среднем только 12% (1,8/15) задач. o1 в среднем решал 74% (11,1/15) с одной выборкой на задачу, 83% (12,5/15) с консенсусом среди 64 выборок и 93% (13,9/15) при повторном ранжировании 1000 выборок с помощью обученной функции оценки. Счет 13,9 помещает его в число 500 лучших студентов страны и выше порога для участия в математической олимпиаде США.
В OpenAI также оценили o1 на GPQA Diamond, сложном бенчмарке интеллекта, который проверяет знания в области химии, физики и биологии. Чтобы сравнить модели с людьми, разработчики наняли экспертов с докторскими степенями для ответа на вопросы GPQA Diamond. Они обнаружили, что o1 превзошел производительность этих экспертов-людей, став первой моделью, сделавшей это на этом бенчмарке. Эти результаты не означают, что o1 во всех отношениях способнее, чем человек с докторской степенью, только то, что модель более искусна в решении некоторых задач, которые, как ожидается, должен решать человек с докторской степенью. На нескольких других бенчмарках машинного обучения o1 улучшил показатели по сравнению с самыми современными моделями. С включенными возможностями визуального восприятия o1 набрал 78,2% на MMMU, став первой моделью, способной конкурировать с экспертами-людьми. Он также превзошел GPT-4o в 54 из 57 подкатегорий MMLU.
Цепочка рассуждений
Подобно тому, как человек может долго думать, прежде чем ответить на сложный вопрос, o1 использует цепочку рассуждений при попытке решить задачу. Благодаря обучению с подкреплением o1 учится оттачивать свою цепочку рассуждений и совершенствовать используемые стратегии. Он учится распознавать и исправлять свои ошибки. Он учится разбивать сложные шаги на более простые. Он учится пробовать другой подход, когда текущий не работает. Этот процесс значительно улучшает способность модели к рассуждению.
Программирование
В OpenAI обучили модель, которая набрала 213 баллов и заняла 49-й процентиль на Международной олимпиаде по информатике (IOI) 2024 года, инициализировав ее из o1 и обучив дальнейшему совершенствованию навыков программирования. Эта модель участвовала в IOI 2024 года на тех же условиях, что и участники-люди. У нее было десять часов, чтобы решить шесть сложных алгоритмических задач, и ей разрешалось 50 попыток на задачу.
Для каждой задачи система генерировала множество вариантов решений и отправляла 50 из них на основе стратегии выбора во время тестирования. Решения выбирались на основе производительности на общедоступных тестовых случаях IOI, тестовых случаях, сгенерированных моделью, и обученной функции оценки. Если бы разработчики вместо этого отправляли решения случайным образом, они бы набрали в среднем всего 156 баллов, что говорит о том, что эта стратегия стоила почти 60 баллов в условиях соревнований.
При ослабленном ограничении на количество попыток разработчики обнаружили, что производительность модели значительно улучшилась. При разрешении 10 000 попыток на задачу модель достигла результата 362,14 балла выше порога золотой медали даже без какой-либо стратегии выбора во время тестирования.
Наконец, в OpenAI смоделировали соревнования по программированию, проводимые Codeforces, чтобы продемонстрировать навыки программирования этой модели. Их оценки точно соответствовали правилам соревнований и допускали 10 попыток. GPT-4o достиг рейтинга Эло 808, что соответствует 11-му процентилю среди участников-людей. Эта модель значительно превзошла как GPT-4o, так и o1 она достигла рейтинга Эло 1807, превзойдя 93% участников.
Дальнейшая тонкая настройка на соревнованиях по программированию улучшает o1. Улучшенная модель заняла 49-й процентиль на Международной олимпиаде по информатике 2024 года в соответствии с правилами соревнований.
Оценка человеческих предпочтений
В дополнение к экзаменам и академическим бенчмаркам в OpenAI также оценили предпочтения людей в отношении o1-preview по сравнению с GPT-4o на сложных, открытых запросах в широком спектре областей. В этой оценке людям-оценщикам были показаны анонимные ответы на запрос от o1-preview и GPT-4o, и они проголосовали за то, какой ответ им больше понравился. o1-preview значительно предпочтительнее GPT-4o в категориях, требующих интенсивного использования логического мышления, таких как анализ данных, программирование и математика. Однако o1-preview не является предпочтительным в некоторых задачах обработки естественного языка, что говорит о том, что он не подходит для всех случаев использования.
Люди предпочитают o1-preview в областях, где полезны мощные рассуждения.
Безопасность
Цепочка рассуждений предоставляет новые возможности для согласования и безопасности. В OpenAI обнаружили, что интеграция их политик поведения модели в цепочку рассуждений модели является эффективным способом надежного обучения человеческим ценностям и принципам. Обучая модель правилам безопасности и тому, как рассуждать о них в контексте, разработчики обнаружили доказательства того, что способность к рассуждению напрямую влияет на надежность модели: o1-preview добился существенного улучшения производительности в ключевых оценках взлома и самых сложных внутренних бенчмарках компании для оценки границ отказа модели в отношении безопасности. Разработчики считают, что использование цепочки рассуждений предлагает значительные преимущества для безопасности и согласования, потому что оно позволяет им наблюдать за мышлением модели понятным образом, и рассуждения модели о правилах безопасности более устойчивы к сценариям, выходящим за рамки распределения.
Чтобы подвергнуть улучшения стресс-тестированию, в OpenAI провели набор тестов безопасности и red-teaming перед развертыванием в соответствии с системой готовности. Разработчики обнаружили, что цепочка рассуждений способствовала улучшению возможностей во всех их оценках. Особо следует отметить, что они наблюдали интересные случаи взлома вознаграждения. Подробные результаты этих оценок можно найти в прилагаемой системной карте o1 на сайте OpenAI.
Заключение
o1 значительно продвигает современные технологии в области рассуждений ИИ. В OpenAI планируют выпускать улучшенные версии этой модели по мере продолжения итераций. Они ожидают, что эти новые возможности рассуждения улучшат их способность согласовывать модели с человеческими ценностями и принципами. Они считают, что o1 и его преемники откроют множество новых вариантов использования ИИ в науке, программировании, математике и смежных областях.





Комментарий